
Mac Apple Silicon LLM 微调实战指南:从原理到多场景应用
Mac Apple Silicon LLM 微调实战指南:从原理到多场景应用
随着 Apple Silicon (M1/M2/M3/M4) 芯片的普及,Mac 已经成为一个强大的 AI 开发工作站。凭借其统一内存架构 (Unified Memory Architecture),Mac 能够处理比同等配置显卡更大的模型。本文将介绍如何在 Mac 上使用 MLX 框架高效微调大语言模型(如 Qwen、Llama、Mistral 等),并探讨微调在不同业务场景中的应用。
一、 核心概念解析
在开始动手之前,我们需要理解几个关键的技术术语。
1. 什么是微调 (Fine-tuning)?
微调是在预训练模型(Base Model)的基础上,使用特定领域的数据进行进一步训练。就像是一个已经读完大学的“通才”,通过学习法律卷宗,变成了一位“律师”。
2. SFT (监督微调)
SFT (Supervised Fine-Tuning) 是最常用的微调方式。它通过 (Input, Output) 对来教导模型如何响应指令。
- 编程场景示例:
- 输入: “帮我写一个 Python 快速排序函数”
- 输出: “[正确的 Python 代码]”
- 医疗问答示例:
- 输入: “患者头晕且伴随耳鸣,可能的原因是什么?”
- 输出: “基于您的症状,可能的原因包括梅尼埃病、前庭神经炎等,建议及时就医进行专业检查。”
- 角色扮演示例:
- 输入: “你现在是苏格拉底,请跟我探讨什么是正义。”
- 输出: “我的朋友,让我们先从定义什么是‘正义’开始,你认为它是强者的利益,还是每个人应得的报酬?”
3. LoRA 与 QLoRA
- LoRA (Low-Rank Adaptation): 这种技术不需要更新模型的所有参数(几十亿个),而是在原有的模型层旁插入一些极小的“旁路矩阵”(Low-Rank Matrices)。训练时只更新这些小矩阵,这极大减少了显存消耗。
- QLoRA: 在 LoRA 的基础上,将原始模型量化到 4-bit。这让 16GB 甚至更小内存的 Mac 也能微调 7B 规模的模型。
二、 为什么要微调?(应用场景)
并不是所有问题都需要微调,但在以下场景中,微调是不可替代的:
- 特定领域知识 (Domain Specific): 当通用模型无法满足极其专业的垂直领域(如医疗诊断、法律合同分析、特定企业内部工作流)时,微调能显著提升准确性。
- 特定的输出格式: 强制模型严格输出特定的 JSON 结构,或遵循复杂的业务逻辑格式。
- 语气与角色对齐: 让 AI 助手拥有特定的品牌性格、客服语调,或是模拟特定历史人物的谈吐。
- 长文本与长指令遵循: 在处理超长上下文或需要严格遵守多步指令的任务中,微调可以提升模型的稳定性。
三、 工欲善其事:基础模型选择的技巧
选择一个合适的基础模型(Base Model)是微调成功的基石。并不是越大的模型就越好,关键在于“适配”。
1. 模型尺寸与显存的博弈
在 Mac 上,显存(统一内存)是核心限制因素:
- 1.5B - 3B 模型: 极其轻量,适合移动端或极其简单的分类/指令遵循任务。16GB 内存的 Mac 可以轻松运行。
- 7B - 9B 模型: 黄金选择。如
Qwen2.5-7B或Llama-3.1-8B。它们在逻辑能力和显存占用之间达到了完美的平衡,适合大多数垂直领域任务。
💡 为什么目前更推荐 Qwen2.5 而非最新的 Qwen3?
虽然 Qwen3 带来了更强的推理能力(如 Thinking Mode)和 MoE 架构,但在微调实践中,Qwen2.5 仍有其独特优势:
- 生态适配极佳:MLX 框架对 Qwen2.5 的算子优化已极其成熟,微调过程非常稳定。
- 专项能力突出:尤其是
Qwen2.5-Coder系列,在代码编写和逻辑推理上的表现依然是开源界的标杆。 - 资源消耗可控:Qwen2.5 采用稠密架构(Dense),在 Mac 的统一内存上表现非常可预测,相比 MoE 架构(Qwen3 部分版本)在微调时更容易控制显存峰值。
- 成熟的微调脚本:社区积累了大量针对 Qwen2.5 的 LoRA 实践经验,避坑更容易。
- 14B - 32B 模型: 适合复杂的逻辑推理。32GB 以上内存的 Mac 建议尝试。
2. 预训练背景的考量
- 通用场景:
Llama-3.1或Qwen2.5是目前最稳妥的选择,它们在海量多语言数据上训练过,泛化能力强。 - 中文场景:
Qwen(通义千问) 系列或DeepSeek系列对中文语境的理解更地道,避坑首选。 - 编程场景: 如果你的目标是微调一个代码助手,直接选用
Qwen2.5-Coder或CodeLlama作为基础模型,会比从通用模型开始微调省力得多。
3. Base vs Instruct 版
- Base 版: 适合续写,没有对话能力。如果你想让模型学习某种特殊的写作风格或大量的纯知识,选 Base 版。
- Instruct/Chat 版: 已经过初步指令对齐,具备对话能力。大多数 SFT 任务建议从 Instruct 版开始,模型更容易“听懂”指令。
4. 协议与商用
务必关注模型的开源协议(如 Apache 2.0, Llama 3 License 等)。如果用于企业内部或产品发布,确保基础模型的协议允许商用。
5. 跨平台视角:Linux + NVIDIA GPU 选型建议
如果你的微调环境是带有 NVIDIA GPU 的 Linux 服务器(如配备 A100, H100 或 RTX 3090/4090),选型逻辑会略有不同:
- Qwen3-30B-A3B / Qwen3-72B: 强烈推荐。Qwen3 在 Linux + CUDA 环境下能完美释放其 MoE(混合专家)架构的潜力。其独特的“思维模式(Thinking Mode)”在处理复杂推理、多语言(支持 119 种)任务时表现惊人。Linux 下的 vLLM 和 LLaMA-Factory 对其算子优化非常超前。
- DeepSeek-V3/R1: 如果你的显存足够(或使用多卡并行),DeepSeek 系列在 Linux/CUDA 生态下有极佳的算子优化,尤其适合需要极高逻辑能力的场景。
- Llama-3.1-70B/405B: 在 Linux 环境下,通过
unsloth或vLLM框架,可以比 Mac 更高效地运行和微调超大规模模型。 - Mistral/Mixtral: 欧洲的“明星”模型,在 Linux 生态下支持非常成熟,适合对隐私和多语言有特殊要求的欧洲或国际业务。
- 优势工具链: 在 Linux 下,你可以使用 Unsloth(速度提升 2x,内存减少 70%)或 LLaMA-Factory。这些工具对 NVIDIA GPU 有原生优化,微调效率远超 Mac。
四、 数据是灵魂:训练数据的获取与管理
在大模型领域有一句话:“Garbage in, garbage out”(输入的是垃圾,输出的也是垃圾)。微调的效果 80% 取决于数据的质量。
1. 数据的组成结构
SFT 数据通常由三个部分组成:
- System: 设置模型的人设(如:“你是一个资深律师”)。
- User: 用户的提问或指令。
- Assistant: 标准的、高质量的回答。
2. 数据获取渠道
- 开源数据集: Hugging Face 和 ModelScope (魔搭社区) 是获取通用数据集的首选。
- 业务日志挖掘: 从真实的业务对话日志中提取 (Input, Output) 对,这是最贴合实际业务的数据来源。
- 合成数据 (Synthetic Data): 使用更强大的模型(如 GPT-4o 或 Claude 3.5)来生成训练数据。
3. 如何自建高质量数据?
如果你没有现成的数据,可以尝试以下方法:
- Self-Instruct: 给模型几个示例,让它仿照示例生成更多的指令和回答。
- 文档转化: 将公司内部的 PDF、Markdown 文档,通过脚本转化为问答对。
- 人工标注: 对于精度要求极高的场景,人工对模型生成的回答进行纠错和润色,形成“黄金数据集”。
五、 实战:环境搭建与微调步骤
本章节将结合环境配置与实际操作,带你完成一次完整的微调流程。
1. 环境准备 (使用 MLX 框架)
本方案推荐使用 MLX,这是苹果专门为 Apple Silicon 优化的深度学习框架。
硬件要求
- 芯片: Apple M1 或更高版本。
- 内存: 建议 32GB 及以上(16GB 内存可微调 7B 量化版)。
数据准备
missvector/linux-commands是一个非常适合初学者练习 Linux 命令微调的高质量数据集。
软件安装 (使用 uv 管理)
1 | # 使用 uv 快速创建环境 |
2. 数据预处理
MLX 推荐使用 .jsonl 格式。数据格式如下:
1 | {"messages": [{"role": "system", "content": "你是一个 Linux 专家"}, {"role": "user", "content": "如何查看进程?"}, {"role": "assistant", "content": "使用 ps -ef 或 top 命令。"}]} |
3. 执行微调
创建一个 config.yaml 配置文件。这里以 Qwen2.5-7B 为例,你也可以替换为 Llama-3 或 Mistral 等模型:
1 | model: "mlx-community/Qwen2.5-7B-Instruct-4bit" |
参数详解与调优实践:
iters(迭代次数): 训练步数。数据量小时(如 < 100 条),建议 100-500 次;数据量大时可增加。注意:次数过多会导致模型“过拟合”,只会背书不会思考。learning_rate(学习率): 决定了模型学习的“步子”有多大。通常在1e-5到5e-5之间。学习率太大模型会学“崩”,太小则学得太慢。rank(LoRA 秩): 核心参数。rank: 8适合简单任务,rank: 32或64适合逻辑复杂或需要学习大量新知识的任务。scale(缩放因子): 决定了微调权重对原始模型的影响程度。通常设为2.0。batch_size: 每次训练喂给模型的数据条数。Mac 内存有限,建议设为1或4。
调参技巧:
如果模型回答开始变得重复或胡言乱语,通常是过拟合了。此时应尝试:1. 减少
iters;2. 调小learning_rate;3. 增加训练数据的多样性。
运行微调命令:
1 | python -m mlx_lm lora --config config.yaml |
4. 部署微调后的模型
对于量化模型,我们采用“基础模型 + 适配器(Adapters)”的方式:
1 | python -m mlx_lm server \ |
六、 效果对比:Cherry Studio 展示
微调效果如何,通过对比一目了然。我们可以使用 Cherry Studio 的“对比模式”进行验证。
- 配置本地端点: 在 Cherry Studio 中添加两个模型:一个指向原始的基础模型,另一个指向加载了 Adapter 的本地服务(端口 8080)。
- 开启对比聊天: 发送一个针对微调场景的特定任务(例如:医疗诊断建议或特定风格的文案)。
对比结果示例(以客服场景为例):
- 微调前: 模型回答:“对不起,我不清楚您指的‘计划 A’是什么。”(通用知识,不了解内部业务)。
- 微调后: 模型回答:“我们的‘计划 A’包含年度基础维护和每季度的安全检查,具体您可以查看内部手册第 5 页。”(精准匹配业务数据)。
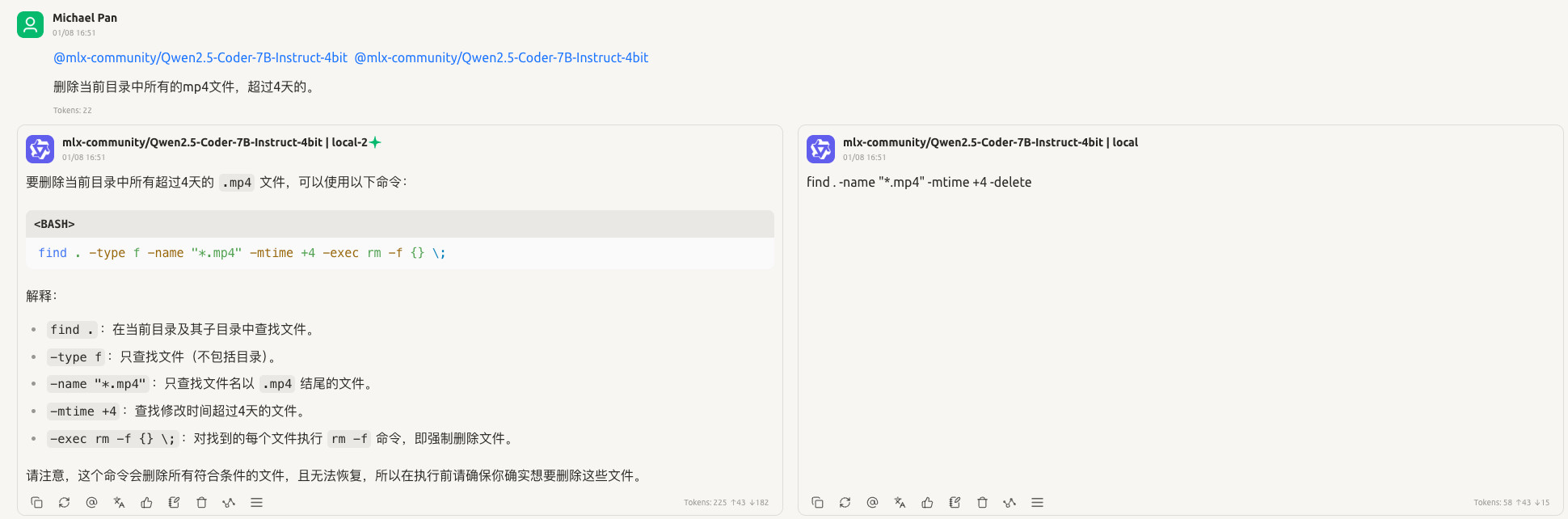
左侧是基础模型,右侧是微调后的模型
七、 性能小贴士
- 统一内存: 在 Mac 上,你可以调整
max_seq_length。如果遇到内存溢出(OOM),适当调小batch_size。 - 监控: 训练时打开“活动监视器”,观察 GPU 的负载。你会发现 M 芯片的 GPU 在矩阵运算上非常高效。
总结
微调不再是昂贵服务器的专利。借助 MLX 框架和 LoRA 技术,每一位 Mac 用户都可以在本地训练出属于自己的“专家模型”。这不仅保护了数据隐私,更为个性化 AI 应用打开了大门。
本文由 AI 辅助生成,如有错误或建议,欢迎指出。





