
《Prometheus监控实战》读书笔记

Prometheus是一个开源的监控系统。
一、监控简介
监控不仅仅只是系统的技术指标,还可以是业务指标。确保为客户提供可靠恰当的产品。
在生产系统中,监控是必须的,它应该和应用程序一起构建和部署。帮助我们了解系统的环境、进行诊断故障、制定容量计划,为组织提供系统的性能、成本和状态等信息。
监控模式
- 务必在项目最开始阶段就把监控考虑进去,它和安全性一样,都是应用的核心功能。
- 根据服务价值设计自上而下的监控系统是一个很好的方式。先是业务逻辑,再是应用程序,最后才是基础设施操作系统。
- 需要找准监控项,及时发现错误
- 通过多样化的数据,如查看数据窗口等更智能的技术分析指标与阀值
- 增加监控的频率
- 尽可能实现监控系统部署实施自动化
监控机制
- 探针与内省:监控应用程序的两种方法。
探针:在应用程序的外部,查询应用程序的外部特征。如Nagios。
内省:查看应用程序的内部内容,经过检测,返回其状态、内部组件等的度量。可用作健康检查接口,由监控工具收集。 - 拉取与推送:执行监控检查的两种方式。
拉取:提取或检查远程应用程序。如Prometheus。
推送:应用程序发送事件给监控系统接收。
监控数据类型
- 指标:软件和硬件组件属性的度量。
指标类型:测量型Gauge、计数型Counter、直方图Histogram - 日志:应用程序发出的事件(通常是文本类型)。
监控方法论
- Brendan Gregg的USE方法
主机级监控
USE:使用率、饱和度、错误。针对每个资源(如CPU),检查使用率(如CPU使用百分比)、饱和度(如等待CPU的进程数)和错误(如错误事件的计数)。 - Google四个黄金指标
应用程序级监控
延迟(如服务请求时间)、流量(如每秒HTTP请求数)、错误(如响应时间走过30ms的请求视为错误)、饱和度(如内存IO)。 - RED方法
Rate(你的服务所服务的每秒的请求数)、Errors(每秒失败的请求数)、Duration(每个请求所花费的时间,用时间间隔表示)
通知系统
通知系统需要关注以下几点:
- 通知清晰、准确、可操作。人易读。
- 通知添加上下文,通知应包含组件的其他相关信息。
- 仅发送有意义的通知。
二、Prometheus是什么?
Prometheus灵感来自于谷歌的Borgmon。这由前谷歌SRE Matt T. Proud开发。Proud加入SoundCloud后,两天Julius Volz合作开发了Prometheus。于2015年1月发布。
Prometheus主要用于提供近实时的、基于动态云环境和容器的微服务、服务和应用的内省监控。Prometheus专注于当前的事件,大多数监控查询和警报都是从最近(通常为一天内)的数据中生成。
Prometheus通过拉取应用程序中暴露的时间序列数据来工作。时间序列数据通常由应用程序本身通过客户端库或exporter的代理来作为HTTP端点暴露。
Prometheus架构
Prometheus有一个推送网关,可用于接收少量数据。
名词解释
endpoint:端点,Prometheus抓取的指标来源
target:目标,定义执行抓取所需的信息,如链接,身份验证,抓取方式
job:一组目标,具有相同角色的目标组
监控资源服务发现
- 用户提供静态资源列表。
- 基于文件的发现。例如使用配置管理工具生成在Prometheus中可以自动更新的资源列表。
- 自动发现。例如,查询consule等数据存储。
聚合和警报
Prometheus服务器可以查询和聚合时间序列数据,创建规则来记录常用的查询和聚合。
Prometheus可以定义警报规则。为系统配置的在满足条件时触发警报的标准。将警报从Prometheus推送到警报管理器(Alertmanager)的单独服务器。
AlertManager可以管理、整合、分发各种警报到不同的目的地。
查询、可视化
Prometheus提供了一套内置查询语言PromQL、一个表达式浏览器及浏览数据的图形界面。
Prometheus可以与开源DashBoard Grafana集成,同时也支持其他的DashBoard。为了速度与可靠性,Prometheus服务器充分使用内存和SSD磁盘
冗余和高可用性
部署Prometheus的高可用模式,可以使用两个以上配置相同的Prometheus服务器来收集时间序列数据,并且生成的警报由Alertmanager集群来处理。
Prometheus数据模型
1 | total_website_visits{site="MegaApp", location="NJ", instance="webserver:9090", job="web"} |
- 指标名称:total_website
- 标签:site=”MegaApp”等,通常都有一个instance标签和job标签
标签分为两类:1,插桩标签;2,目标标签
插桩标签:来自被监控的资源
目标标签:通常与架构相关,由Prometheus在抓取期间和之后添加。 - 时间序列由名称和标签标识,如果在时间序列中添加或更改标签,Prometheus会将其视为新的时间序列。
三、安装部署Prometheus
安装Prometheus
Linux上安装Prometheus
- 下载Prometheus的二进制文件shell
1
wget https://github.com/prometheus/prometheus/releases/download/v2.14.0/prometheus-2.14.0.linux-amd64.tar.gz
- 解压文件到相关目录,安装promtoolshell
1
2
3tar -xzf prometheus-2.14.0.linux-amd64.tar.gz
sudo cp prometheus-2.14.0.linux-amd64/prometheus /usr/local/bin/
sudo cp prometheus-2.14.0.linux-amd64/promtool /usr/local/bin/ - 执行prometheus –version查看版本验证安装。
Ansible安装Promethues
相关的role路径为:https://github.com/cloudalchemy/ansible-prometheus。
OpenShift上安装Prometheus
OpenShift官方部署脚本支持Prometheus的安装。在OpenShift 3.11部署的时候,prometheus默认是安装的,如果要禁止安装则需将inventory中的配置openshift_cluster_monitoring_operator_install设置为false。
相关的开源软件地址为:https://github.com/openshift/cluster-monitoring-operator
配置Prometheus
Prometheus通过YAML文件来配置。Prometheus的解压的目录中自带有配置文件prometheus.yml。
1 | global: |
global:全局配置
alerting:设置Prometheus的警报。Prometheus支持Alertmanager服务发现功能。
rule_files:指定包含记录规则或警报规则的文件列表。
scrape_configs:指定Prometheus抓取的所有目标。
运行Prometheus
- 将配置文件prometheus.yml移到合适的位置shell
1
2sudo mkdir -p /etc/prometheus
sudo cp prometheus.yml /etc/prometheus/ - 运行prometheus应用shell
1
prometheus --config.file "/etc/prometheus/prometheus.yml"
- 如果发生异常,可以使用promtool来验证配置文件shell
1
2
3promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 0 rule files found
查询数据
- 查看指定指标值shell
1
go_gc_duration_seconds{quantile="0.5"} 1.6166e-05
- 过滤一些匹配标签shell
1
go_gc_duration_seconds{quantile!="0.5"}
- 聚合数据求和shell
1
sum(promhttp_metric_handler_requests_total) # 求和
- PromQL通过子名by,按特定维度聚合shell
1
sum(promhttp_metric_handler_requests_total) by (job)
- 转换成速率rate()函数计算一定范围内时间序列的每秒平均增长率,适合缓慢变化的计数器(counter)。shell
1
sum(rate(promhttp_metric_handler_requests_total[5m])) by (job)
irate()函数计算指定时间范围内的最近两个数据点来算速率,适合快速变化的计数器(counter)。
rate()与irate()函数都必须与计数器一起使用。 - 增加数量指标1小时内增长的值。shell
1
increase(promhttp_metric_handler_requests_total[1h])
容量规划
- 内存
通过以下查询语句查看样本的收集率。显示最后一分钟添加到数据库的每秒样本率。
1 | rate(prometheus_tsdb_head_samples_appended_total[1m]) |
查询收集的指标数量,通过以下语句
1 | sum(count by (__name__)({__name__-\~"\.\+"})) |
每个样本大小通常为1到2字节,假设在12小时内每秒收集100000个样本,那么内存使用情况为
1 | 100000 * 2 bytes * 43200秒 约为 8.64GB内存 |
约为 8.64GB内存,还需要考虑查询与记录规则方面内存的使用情况。
可以通过查看process_resident_memory_bytes指标查看Prometheus进程的内存使用情况。
2. 磁盘
默认情况下,指标会在本地数据库中存储15天。具体时间由命令行选项控制。
–storage.tsdb.path: 设置数据存储目录,默认为Prometheus的目录中。
–storage.tsdb.retention: 设置时间序列保留期,默认为15天。建议采用SSD作为时间序列数据库的磁盘
每秒10万个样本的示例,每个样本磁盘上占用约1~2字节,保留15天数据算,大约需要259GB磁盘。
四、监控主机和容器
Prometheus通过使用exporter工具来暴露主机和应用程序的指标。常用的exporter列表可在以下网站上查看。
1 | https://prometheus.io/docs/instrumenting/exporters/ |
监控主机
Node Exporter 是用GO语言编写的,收集各种主机指标数据(CPU/内存/磁盘等)。同时还有一个textfile收集器,允许导出静态指标。
- 安装Node Exporter
Node Exporter的下载地址如下:下载并解压安装shell1
https://github.com/prometheus/node_exporter
shell1
2
3wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
tar -xzf node_exporter-*
sudo cp node_exporter-*/node_exporter /user/local/bin/ - 配置Node Exporter
node_exporter是通过执行命令时传入参数来配置。默认情况下node_exporter在端口9100上运行,路径为/metrics。可通过–web.listen-address和–web.telemetry-path来设置shell1
2node_exporter --help
同时可以通过参数控制启动的收集器,默认的收集器可在以下地址中查看shell1
node_exporter --web.listen-address=":9600" --web.telemetry-path="/node_metrics"
例如,想要禁用/proc/net/arp统计信息,只需要启动node_exporter时添加shell1
https://github.com/prometheus/node_exporter#enabled-by-default
--no-collector.arp配置项。 - 配置textfile收集器
textfile收集器可以帮助我们暴露自定义指标。node_exporter通过参数--collector.textfile.directory参数指定textfile的目录,它会扫描该目录下的所有文件,提取所有格式为Prometheus指标的字符串,然后暴露它们。shell1
2mkdir -p /var/lib/node_exporter/textfile_collector
echo 'metadata{role="docker_server", datacenter="NJ"} 1' | sudo tee /var/lib/node_exporter/textfile_collector/metadata.prom - 启用systemd收集器
systemd收集器记录systemd中的服务和系统状态。首先需要通过参数--collector.systemd启用该收集器,同时如果不希望收集所有的服务,只收集部分关键服务。node_exporter在启动时可以使用--collector.systemd.unit-whitelist参数配置。 - 运行Node Exporter
启动node_exporter的实例shell1
node_exporter --collector.textfile.director /var/lib/node_exporter/textfile_collector --collector.systemd --collector.systemd.unit-whitelist-{(docker|ssh|rsyslog).service"
- 抓取Node Exporter
配置新作业来抓取Node Exporter导出的数据。prometheus.yml文件中的scrape_configs部分添加job添加了新的job ‘node’,添加了三台主机的node_exporter监控,默认路径为/metrics。shell1
2
3
4
5
6
7scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.0.3:9100', '192.168.0.4:9100', '192.168.0.5:9100']
重启Prometheus服务,将会加载最新的配置,新监控项将会被收集到prometheus数据中。 - 过滤收集器
Prometheus提供了限制抓取过来的数据指标的机制。使用params块中的collect[]来指定收集的指标。使用以下命令来模拟测试shell1
2
3
4
5
6
7
8
9
10
11
12
13
14
15scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['192.168.0.3:9100', '192.168.0.4:9100', '192.168.0.5:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- netstat
- filefd
- filesystem
- xfs
- systemdshell1
curl -g -X GET http://192.168.0.3:9100/metrics?collect[]=cpu
监控Docker容器
推荐使用Google的cAdvisor工具来监控Docker。cAdvisor作为Docker容器运行,单个cAdvisor容器返回针对Docker守护进程和所有正在运行的容器的指标。
- 运行cAdvisor通过浏览器访问http://192.168.0.3:8080/containers/可查看shell
1
2
3
4
5
6
7
8
9docker run \
-v /:/rootfs:ro \
-v /var/run:/var/run:rw \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
-v /dev/disk/:/dev/disk:ro \
-p 8080:8080 \
-d --name=cadvisor \
google/cadvisor:latest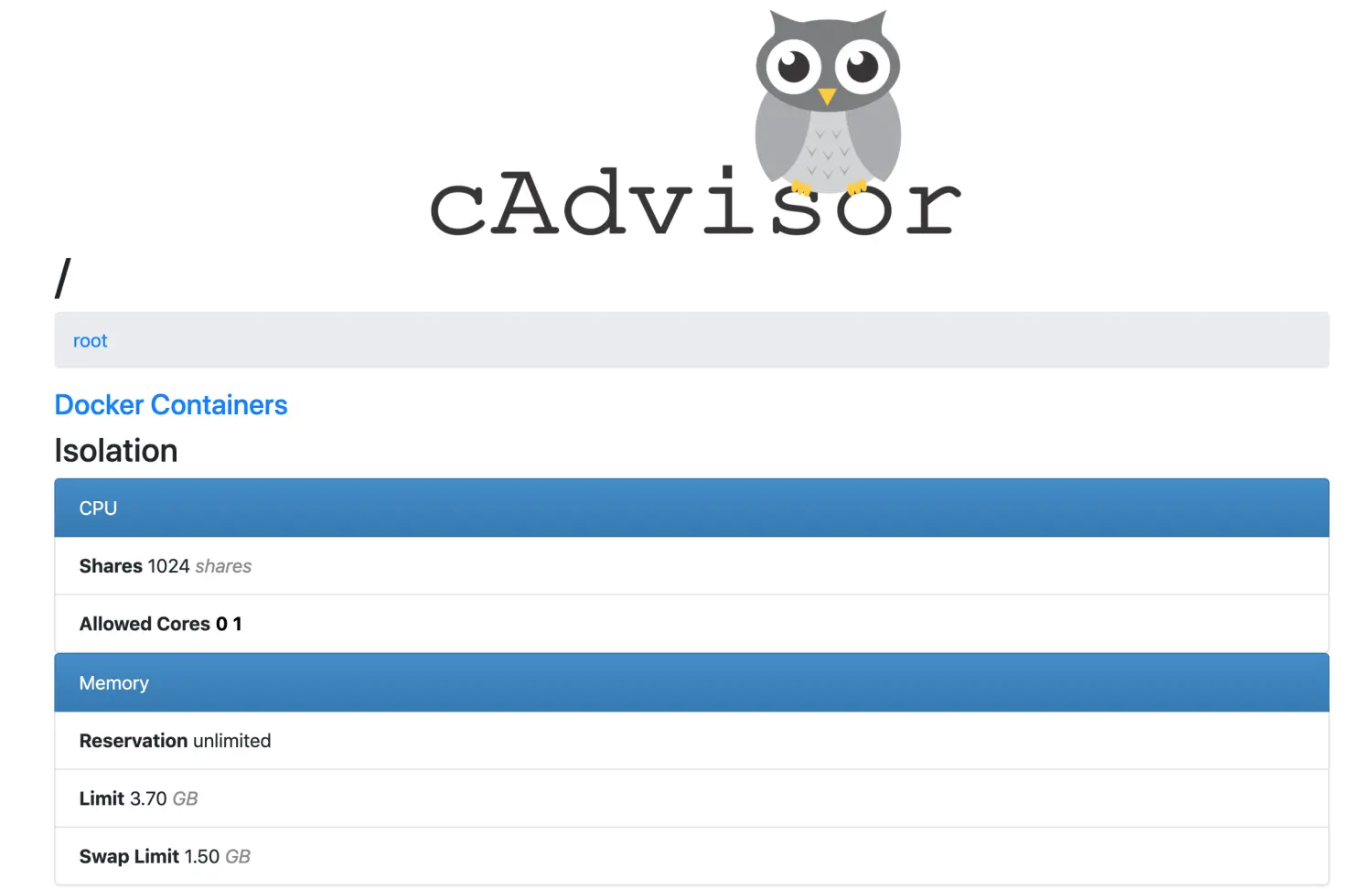
通过浏览器访问http://192.168.0.3:8080/metrics查看暴露的内置Prometheus指标
- 抓取cAdvisor
配置新作业来抓取cAdvisor导出的数据。prometheus.yml文件中的scrape_configs部分添加job添加了新的job ‘docker’,添加了三台主机的node_exporter监控,默认路径为/metrics。shell1
2
3
4
5
6
7
8
9
10scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.0.3:9100', '192.168.0.4:9100', '192.168.0.5:9100']
- job_name: 'docker'
static_configs:
- targets: ['192.168.0.3:8080', '192.168.0.4:8080', '192.168.0.5:8080']
Prometheus抓取数据的生命周期

可以看到在Prometheus抓取数据的生命周期中,有两处重新标记指标的部分,一个在抓取前,一个是在抓取后。
标签
标签提供了时间序列的维度,可以定义目标,并为时间序列提供上下文。最重要的是,结合指标名称,它们构成了时间序列的标识。
更改或者添加标签会创建新的时间序列
标签分类:拓扑标签、模式标签
拓扑标签:通过其物理或者逻辑组成来切割服务组件。每个指标都天然带着job和instance两个拓扑标签。instance标签可以标识目标,通常是目标的IP地址和端口,并且来自__address__标签。
模式标签:url、error_code或者user之类,允许将拓扑中同一级别的时间序列匹配在一起。
如果需要添加额外的标签,可以考虑以下的层次结构
重新标记
控制标签。有两个阶段可以重新标记标签。抓取前的relabel_configs和抓取后的metric_relabel_configs模式。
- 删除不必要的指标
- 从指标中删除敏感或不需要的标签
- 添加、编辑、修改指标的标签值或标签格式
在拉取了cAdvisor的指标数据后,删除
container_tasks_state与container_memory_failures_total指标数据
1 | - job_name: 'docker' |
separator默认值为’;’,多个标签通过separator连接在一起。
如果指定多个源标签,可以使用;隔开每个正则表达式。
action: drop将会在数据存储之前删除指标,keep则会保留与正则匹配的指标,删除所有其他指标。
正则配置id指标中的数据,并将匹配的值放入新的标签container_id中。
1 | - job_name: 'docker' |
没有指定action操作,因为metric_relabel_configs的action默认操作为replace。
honor_labels默认值为false,如果target_label的标签已经存在,则会在其前面添加exported_前缀来做区分。
删除标签kernelVersion
1 | - job_name: 'docker' |
action: labeldrop,删除匹配的标签
action: labelkeep,保留匹配的标签,删除所有其他标签
Node Exporter和cAdvisor指标
- CPU使用率shell
1
100 - avg(irate(node_cpu_seconds_total{job="node", mode="idle"}[5m])) by (instance) * 100
- CPU饱和度shell
1
node_load1 > on (instance) 2 * count by (instance)(node_cpu_seconds_total{mode="idle"})
- 内存使用率shell
1
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100
- 内存饱和度shell
1
1024 * sum by (instance) ((rate(node_vmstat_pgpgin[1m]) + rate(node_vmstat_pgpgout[1m])))
- 磁盘使用率Prometheus支持预测shell
1
(node_fileystem_size_bytes{mountpoint=~"/|/run"} - node_filesystem_free_bytes{mountpoint=~"/|/run"}) / node_filesystem_size_bytes{mountpoint=~"/|/run"} * 100
使用1个小时窗口数据,预测所有磁盘4个小时后的磁盘会不会用完。shell1
predict_linear(node_fileystem_size_bytes{job="node"}[1h], 4*3600) < 0
- 服务状态shell
1
node_systemd_unit_state{name="docker.service", state="active"}
- exporter的可用性和up指标shell
1
up {job="node", instance="192.168.0.3:9100"}
- textfile收集器metadata指标on:一对一匹配shell
1
2metadata{datacenter != "NJ"}
node_systemd_unit_state{name="docker.service"} == 1 and on (instance, job) metadata{datacenter = "SF"}
group_left:多对一
group_right:一对多
详情:https://prometheus.io/docs/prometheus/latest/querying/operators/#vector-matching
查询持久化
三种方式使查询持久化
- 记录规则:根据查询创建新指标
- 警报规则:从查询生成警报
- 可视化:使用Grafana等仪表板可视化查询
记录规则
prometheus.yml中的配置项evaluation_interval设置为自动计算记录的规则。
1 | global: |
在prometheus.yml文件的同一文件夹下,创建名为rules的子文件夹,用于保存记录规则。同时在prometheus.yml配置文件中的rule_files块中添加文件rules/node_rules.yml
1 | mkdir -p rules && cd rules |
创建了名为”node_rules”的规则组,顺序执行规则,后面的规则可以重用前面的规则。规则组间是并行运行的,因此不建议跨组使用规则。
interval:10s 可以设置interval覆盖默认的evaluation_interval值。
record:应该仔细为新的时间序列取名,以便快速识别它的含义,一般推荐的格式是: level:metric:operations
expr:保存生成新时间序列的查询
labels:向新序列添加新的标签
可视化 Grafana
- 安装Grafana使用ansible role安装:https://galaxy.ansible.com/list#roles/3563shell
1
2wget https://dl.grafana.com/oss/release/grafana-6.5.1-1.x86_64.rpm
sudo yum localinstall grafana-6.5.1-1.x86_64.rpm
使用Docker镜像安装:https://hub.docker.com/search/?q=grafana - 启动与配置Grafana
配置文件位于/etc/grafana/grafana.inishell1
systemctl start grafana-server
- 浏览器访问http://localhost:3000,默认用户名和密码为admin和admin。
Grafana仪表盘实例查看地址:https://grafana.com/grafana/dashboards
五、Prometheus服务发现
对于主机数少的情况下,Prometheus可以使用静态配置目标。当规模较大的集群时,就不适用了。服务发现可以通过以下三种机制实现:
- 配置管理工具生成的文件中接收目标列表
- 查询API以获取目标列表
- 使用DNS记录以返回目标列表
基于文件的服务发现
适合配置管理工具。Prometheus会按指定时间计划从这些文件重新加载目标,文件格式支持yaml、Json格式,它们包含了目标列表。
1 | - job_name: node |
新建nodes与docker目录,并添加对应的配置文件
1 | cd /etc/prometheus |
基于API的服务发现
当前API的服务发现支持以下平台:
- AWS EC2
- Azure
- Consul
- Google Compute Cloud
- Kubernetes
基于DNS的服务发现
1 | - job_name: webapp |
Prometheus在查询目标时,通过DNS服务器查找example.com域,然后在该域下搜索名为_prometheus._tcp.example.com的SRV记录,返回该条目中的服务记录。
还可以使用DNS服务发现来查询单个A或AAAA记录。
1 | - job_name: webapp |
返回example.com域根目录下的所有A记录。
六、Alert Manager报警管理
监控是为了了解系统的状态,以便于及时发现问题。当指标出现异常时,我们应该第一时间知道,便及时处理,但是我们又无法实时关注在每个监控指标,这时我们就需要告警机制。没有告警机制的监控,像是摆在家里的花瓶,它很美但用处不大。
一个好的警报应该是,在正确的时间、发给正确的人、恰当的量、包含准确(不多也不少)的信息。
- 适当数量的警报
- 设置正确的警报优先级
- 警报应包括适当的上下文
Alertmanager如何工作
Prometheus服务器向Alertmanager发送警报,当然Alertmanager也可以接收其他工具的警报。Alertmanager对警报进行去重、分组,然后路由到不同的接收器:email,sms等。
- 在Prometheus服务上编写警报规则
- 当指标达到阈值时,会生成警报推送到Alertmanager。
- 一个或多个Prometheus服务器可以将警报定向到单个Alertmanager下
- Alertmanager处理警报,并根据其标签进行路由。
Alertmanager安装、配置、运行
- Alertmanager安装shell
1
2
3
4wget https://github.com/prometheus/alertmanager/releases/download/v0.20.0-rc.0/alertmanager-0.20.0-rc.0.linux-amd64.tar.gz
tar -xzf alertmanager-0.20.0-rc.0.linux-amd64.tar.gz
sudo cp alertmanager-0.20.0-rc.0.linux-amd64/alertmanager /usr/local/bin/
sudo cp alertmanager-0.20.0-rc.0.linux-amd64/amtool /usr/local/bin/ - 配置Alertmanager
https://prometheus.io/docs/alerting/configuration/global:全局设置,为其他模块的默认值shell1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18sudo mkdir -p /etc/alertmanager
sudo cat > /etc/alertmanager/alertmanager.yml <<EOF
global:
smtp_smarthost: 'localhost:25'
smtp_from: 'alertmanager@example.com'
smtp_require_tls: false
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
receiver: email
receivers:
- name: 'email'
email_configs:
- to: 'alerts@example.com'
EOF
template:保存警报模板
route:警报根据规则进行匹配,采取相应的操作
receivers:接收器列表,每个接收器有唯一的名字及配置。email_configs来指定电子邮件选项,webhook_configs可以扩展Alertmanager的接收器。 - 运行Alertmanager通过浏览器访问alertmanager,http://localhost:9093shell
1
alertmanager --config.file alertmanager.yml
Prometheus配置Alertmanager
- 在prometheus.yml配置中设置alerting模块。shell
1
2
3
4
5alerting:
alertmanagers:
- static_configs:
-targets:
- alertmanager:9093 - 监控Alertmanager
Alertmanager服务暴露了自身的相关指标,创建一个Prometheus Job就可以监控Alertmanagershell1
2
3- job_name: 'alertmanager'
static_configs:
- targets: ['localhost:9093'] - 添加警报规则
与记录规则一样,警报规则在Prometheus服务器配置中加载的规则文件内也使用Yaml语句定义。
在prometheus.yml配置文件中的rule_files块中添加文件rules/node_alerts.yml
在rules目录下创建文件node_alerts.yml来保存节点报警规则。alert:规则名shell1
2
3
4
5
6
7
8
9
10
11
12
13cat > rules/node_alerts.yml <<EOF
groups:
- name: node_alerts
rules:
- alert: HighNodeCPU
expr: instance:node_cpu:avg_rate5m > 80
for: 60m
labels:
severity: warning
annotations:
summary: High Node CPU for 1 hour
console: You might want to check the Node Dashboard at http://grafana.example.com/dashboard/db/node-dashboard
EOF
expr:触发规则
for:控制在触发警报之前测试表达式必须为true的时长
labels与annotations:装饰警报
警报有三种状态:
Inactive:警报未激活
Pending:警报已满足测试表达式条件,但仍在等待for子句中指定的持续时长
Firing:警报(如果没有设置for,则一旦触发条件,立刻Firing)
Pending、Firing状态下的警报可以在Prometheus的指标中查看到ALERTS。
新的警报与模板示例
1 | groups: |
路由
Alertmanager的配置文件alertmanager.yml中添加一些路由配置。
1 | route: |
group_by:对Alertmanager警报指定分组方式,如按照instance来分组
group_wait:如果进行分组,Alertmanager会等待group_wait指定的时间,以便在触发报警前查看是否收到该组中的其他报警
group_interval:如果发出警报后,Alertmanager收到该分组的下一次评估的新警报后,会等待group_interval时间后再发送新警报,以免警报泛滥
repeat_interval:适用于单个警报,等待重新发送相同警报的时间段
receiver:默认接收器
send_resolved: 恢复后发送通知
routes:路由规则。如果需要routers还可以分支。如:
1 | routes: |
通知模板
模板目录:/etc/alertmanager/templates
1 | cat > /etc/alertmanager/templates/slack.tmpl <<EOF |
对应的slack_configs receiver配置
1 | slack_configs: |
使用模板通知来填充text字段,使用上下文通知。
silence和维护
报警静默设置。当服务进行维护时,不需要发出告警,使用silence进行控制。两种方法进行设置:
- 通过Alertmanger Web控制台
- 通过amtool命令工具
- 使用amtool添加silence。默认为1h过期时间,可以指定–expires和–expire-on参数指定更长的时间与窗口shell
1
amtool --alertmanager.url=http://localhost:9093 silence add alertname=InstancesGone service=application1
- 使用query命令查询silence列表shell
1
amtool --alertmanager.url=http://localhost:9093 silence query
- 指定silence过期shell
1
amtool --alertmanager.url=http://localhost:9093 silence expire $SILENCE_ID
- 使用正则创建silenceshell
1
amtool --alertmanager.url=http://localhost:9093 silence add --comment "App1 maintenance" alertname=~'Instance.*' service=application1
七、Prometheus高可用性
Prometheus通过运行两个配置相同的Prometheus服务器,并且它们同时处于活动状态来实现容错。该配置生成的重复警报交由上游Alertmanager使用其分组功能进行处理。所以一个推荐的做法是关注Alertmanager的高可用,而不是Prometheus服务。
通过创建一个Alertmanager集群来实现高可用,所有Prometheus服务器将告警发送到Alertmamanager集群,而Alertmanager负责去除重复数据。
设置Alertmanager集群
Alertmanager包含由HashiCorp Memberlist库提供的集群功能。
- 在多台主机上安装Alertmanager
- 启动Alertmanager,传入参数–cluster.listen-address
第一台主机启动Alertmanager命令如下:剩下的主机启动Alertmanager命令如下:shell1
alertmanager --config.file alertmanager.yml --cluster.listen-address 192.168.0.3:8001
shell1
alertmanager --config.file alertmanager.yml --cluster.listen-address 192.168.0.4:8001 --cluster.peer 192.168.0.3:8001
- 在Alertmanager的控制台状态页面/status上查看集群状态
- 为Prometheus配置Alertmanager集群三个Alertmanager服务都会收到告警信息,保证告警可达。shell
1
2
3
4
5
6
7alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.3:9093
- 192.168.0.4:9093
- 192.168.0.5:9093
可扩展性
Prometheus federation API抓取每个工作节点的聚合指标
一个很好的例子是:基于区域的主节点和工作节点,基于区域的主节点视为全局的工作节点,然后向全局的主节点进行报告。
因为是金字塔级结构,主节点可能会有延时,所以尽量通过工作节点向Alertmanager发送告警。
水平分片通常是最后的选择。每个目标都有数万个指标或者大量时间序列。
Prometheus work0配置
1 | global: |
该过程是使用hashmod模块对__address__标签的值对3取Mod,如果余数为0,则保留。
同样的方法配置好work1与work2节点。
Prometheus 主节点配置
1 | scrap_configs: |
其中targets/workers.json内容为
1 | [{ |
Prometheus支持使用/federate API根据指定的匹配参数来查询服务器指标。
八、日志监控
使用mtail作为日志处理工具,它是Google开发的,非常轻巧。它专门用于从应用程序日志中提取要导出到时间序列数据库中的指标。
- 安装mtailshell
1
2
3wget https://github.com/google/mtail/releases/download/v3.0.0-rc33/mtail_v3.0.0-rc33_linux_amd64 -O mtail
chmod 0755 mtail
sudo cp mtail /usr/local/bin/ - 使用mtail
mtail通过命令进行配置,指定日志文件列表,以及运行的程序目录。每个mtail程序都以.mtail为后缀名。程序定义了一个名为line_count的计数器(计数器 counter,测量型 gauge)。这些计数与测量通过mtail导出到定义的任何目的地。shell1
2
3
4
5
6
7
8sudo mkdir /etc/mtail
cat > /etc/mtail/line_count.mtail <<EOF
counter line_count
/ {
line_count++
}
EOF - 运行mtail–progs:指定mtail程序所在目录shell
1
sudo mtail --progs /etc/mtail --logs '/var/log/*.log'
–logs:指定日志文件
执行后,mtail将在3903端口上启动Web服务(使用–address和–port参数设置IP与端口)。http://localhost:3903/metrics路径可以被Prometheus获取相关监控数据。
处理Web服务器访问日志
1 | LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer|i\" \"%}User-agent|i\" |
by:指定要添加到指标的其他维度,它们将会添加到指标的标签中。
每个维度包含在[ ]中。
运行mtail程序
1 | sudo mtail --progs /etc/mtail --logs '/var/log/apache/*.access' |
解析Rail日志到直方图
1 | counter rails_requests_started_total |
尽量为每个应用单独部署日志监控,对于K8S上的应用,可以使用sidecar的方式运行mtail来实现日志监控。
例子代码:https://github.com/google/mtail/tree/master/examples
九、探针监控
使用Blackbox exporter来对外部服务探测监控。
- 安装Blackbox exportershell
1
2
3wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.16.0/blackbox_exporter-0.16.0.linux-amd64.tar.gz
tar -xzf blackbox_exporter-0.16.0.linux-amd64.tar.gz
sudo cp blackbox_exporter-0.16.0.linux-amd64/blackbox_exporter /usr/local/bin/ - 配置Blackbox exporter
使用/etc/prober/prober.yml文件配置exportershell1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21sudo mkdir -p /etc/prober
sudo touch /etc/prober/prober.yml
cat > /etc/prober/prober.yml <<EOF
modules:
http_2xx_check:
prober: http
timeout: 5s
http:
valid_status_codes: []
method: GET
icmp_check:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: "ip4"
dns_examplecom_check:
prober: dns
dns:
preferred_ip_protocol: "ip4"
query_name: "www.example.com"
EOF - 启动exporter默认在端口9115下运行服务:http://localhost:9115/metricsshell
1
sudo blackbox_exporter --config.file="/etc/prober/prober.yml"
- Prometheus创建作业,调用Blackbox Exporter服务Blackbox Exporter的配置Job方式与其他作业不同,这的targets是作为Blackbox Exporter检测的目标地址。而Blackbox Exporter的服务地址,通过relabel_configs替换掉__address__标签的方式设置。shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17scrape_configs:
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx_check] # Look for a HTTP 200 response.
static_configs:
- targets:
- http://prometheus.io # Target to probe with http.
- https://prometheus.io # Target to probe with https.
- http://example.com:8080 # Target to probe with http on port 8080.
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
十、Pushgateway方式推送监控数据
Prometheus主要是基于拉取的架构来运行作业,同时也提供了Pushgateway服务来支持Push方式。
Pushgateway位于发送指标的应用程序与Prometheus服务器之间,接收指标,同时作为目标被抓取。
Pushgateway只能用作有限的解决方案使用,特别是监控其他无法访问的资源。
- 安装Pushgatewayshell
1
2
3wget https://github.com/prometheus/pushgateway/releases/download/v1.0.0/pushgateway-1.0.0.linux-amd64.tar.gz
tar -xzf pushgateway-1.0.0.linux-amd64.tar.gz
sudo cp pushgateway-1.0.0.linux-amd64/pushgateway /usr/local/bin - 配置和运行Pushgateway–web.listen-address:指定服务端口。pushgateway默认端口是9091.shell
1
pushgateway --web.listen-address="0.0.0.0:9091" --persistence.file="/tmp/pushgateway_persist" --persistence.interval=5m
–persistence.file:指标持久化到路径。默认情况下,pushgateway所有指标存储在内存中,如果pushgateway停止服务或者重新启动,所有数据将会丢失。
–persistence.interval:指标持久化写入周期。默认5m - 向pushgateway服务发送指标将为作业batchjob1添加一个新的指标shell
1
echo "batchjob1_user_counter 2" | curl --data-binary @- http://localhost:9091/metrics/job/batchjob1/instance/sidekiq_server
batchjob1_user_counter{instance="sidekiq_server"} 2也可以同时发送多个指标。shell1
2
3
4cat <<EOF | curl --data-binary @- http://localhost:9091/metrics/job/batchjob1/instance/sidekiq_server
TYPE batchjob1_user_counter counter
HELP batchjob1_user_counter A metric from BatchJob1.
batchjob1_user_counter{job_id="123ABC"} 2 - 在pushgateway上查看指标shell
1
curl http://localhost:9091/metrics
- 删除pushgateway上的指标shell
1
2curl -x DELETE localhost:9091/metrics/job/batchjob1 #删除job batchjob1下的所有指标
curl -x DELETE localhost:9091/metrics/job/batchjob1/instance/sidekiq_server # 删除job batchjob1下标签满足instance=sidekiq_server的指标 - Promethes上添加Pushgateway Jobhonor_labels设置为true,Prometheus使用Pushgateway上的job和instance标签,否则会在前面加上exported_前缀。shell
1
2
3
4- job_name: 'pushgateway'
honor_labels: true
static_configs:
- targets: ['localhost:9091']
十一、监控OpenShift
OpenShift平台的监控方案默认为Prometheus开源监控方案,它不仅带有一整套完成的监控,而且还预配置了一组告警,以及一组丰富的Grafana仪表盘。

可以通过Prometheus Operator方便地创建、配置和管理Prometheus及Alertmanager。
从上图可以看到,除了Prometheus与Alertmanager服务,OpenShift的监控方案中还装了node exporter与kube-state-metrics获取集群的状态指标。
OpenShift使用ansible安装时,默认会安装的cluster monitoring operator。除非在inventory中指定openshift_cluster_monitoring_operator_install为false。

扩展资料






未找到相关的 Issues 进行评论
请联系 @xhuaustc 初始化创建