从零构建RAG文档问答系统:技术栈与实现方案详解
引言
在人工智能快速发展的今天,如何让AI模型基于特定文档内容进行准确回答,成为了一个重要的技术挑战。传统的问答系统往往存在”幻觉”问题,即模型会生成看似合理但实际不准确的信息。为了解决这个问题,我们构建了一个基于RAG(Retrieval-Augmented Generation)技术的文档问答系统。
本文将详细介绍这个项目的技术栈选择、架构设计、实现方案以及开发过程中的关键决策。
项目概述
项目源代码: https://github.com/xhuaustc/rag-qa-system
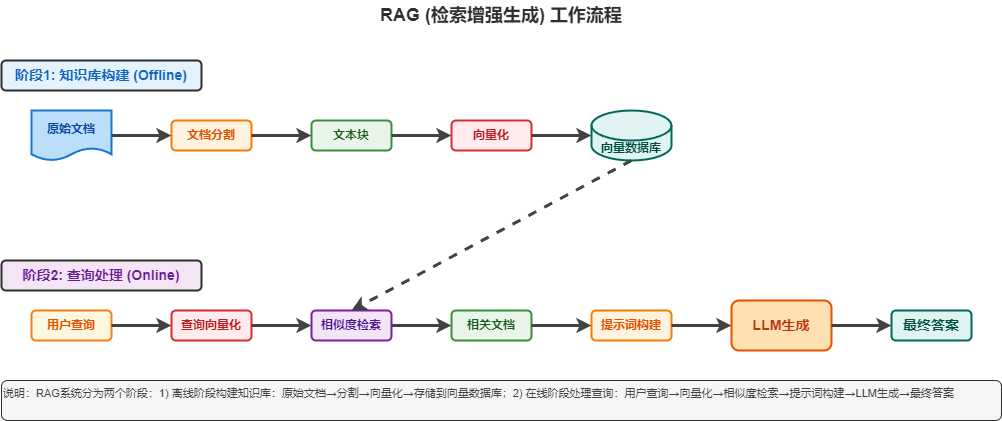
我们的RAG文档问答系统具有以下核心特性:
- 🔍 多格式文档支持: PDF、DOCX、Markdown、TXT等
- 🤖 多LLM后端: Ollama、OpenAI、Azure OpenAI
- 📝 智能文档分块: 支持中英文混合文本的智能分块
- 🔗 向量检索: 基于ChromaDB的高效向量检索
- 💬 智能问答: 基于文档内容的智能问答
- ⚙️ 灵活配置: 支持环境变量和代码配置
- 🛠️ 模块化设计: 清晰的模块分离和扩展性
技术栈选择
核心框架
LangChain: 作为我们的核心框架,LangChain提供了丰富的LLM集成、文档处理和向量存储功能。它支持多种LLM提供商,并且有良好的扩展性。
1
2
3
4
5
|
langchain>=0.1.0
langchain-community>=0.0.10
langchain-openai>=0.0.5
langchain-ollama>=0.1.0
|
ChromaDB: 选择ChromaDB作为向量数据库,主要考虑其以下优势:
- 轻量级,易于部署
- 支持本地存储,无需额外服务
- 良好的Python集成
- 支持元数据过滤
LLM提供商
我们支持三种主要的LLM提供商:
- Ollama: 本地部署,隐私保护,成本可控
- OpenAI: 云端服务,性能稳定,功能丰富
- Azure OpenAI: 企业级服务,合规性好
文档处理
1
2
3
4
5
6
|
markdown>=3.5.0
pypdf>=3.17.0
python-docx>=1.1.0
docx2txt>=0.8
unstructured>=0.11.0
|
系统架构设计
整体架构
我们的系统采用模块化设计,主要包含以下几个核心模块:
1
2
3
4
5
6
7
| ollama/
├── config/ # 配置管理
├── doc_proc/ # 文档处理
├── embed/ # 嵌入处理
├── llm/ # LLM客户端
├── utils/ # 工具模块
└── main.py # 主程序
|
核心模块详解
1. 配置管理模块 (config/)
使用Python的dataclasses模块构建了层次化的配置系统:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @dataclass
class LLMConfig:
"""LLM客户端配置"""
provider: str = field(default_factory=lambda: os.getenv("LLM_PROVIDER", "ollama"))
model: str = field(default_factory=lambda: os.getenv("LLM_MODEL", "qwen3:8b"))
embedding_model: str = field(default_factory=lambda: os.getenv("LLM_EMBEDDING_MODEL", "shaw/dmeta-embedding-zh"))
api_key: Optional[str] = field(default_factory=lambda: os.getenv("LLM_API_KEY"))
base_url: str = field(default_factory=lambda: os.getenv("LLM_BASE_URL", "http://localhost:11434"))
@dataclass
class AppSettings:
"""应用程序设置"""
llm: LLMConfig = field(default_factory=LLMConfig)
storage: StorageConfig = field(default_factory=StorageConfig)
document_processing: DocumentProcessingConfig = field(default_factory=DocumentProcessingConfig)
|
这种设计的优势:
- 类型安全: 使用dataclass提供类型检查
- 环境变量集成: 自动从环境变量读取配置
- 默认值: 提供合理的默认配置
- 验证: 支持配置验证逻辑
2. LLM客户端模块 (llm/)
采用工厂模式和策略模式设计LLM客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class BaseLLMClient(ABC):
"""LLM客户端基类"""
@abstractmethod
def generate_text(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""生成文本"""
pass
@abstractmethod
def generate_embeddings(self, texts: List[str]) -> List[List[float]]:
"""生成嵌入向量"""
pass
class OllamaLLMClient(BaseLLMClient):
"""Ollama LLM客户端"""
def __init__(self, config: LLMConfig):
self.config = config
self._initialize_components()
def _initialize_components(self) -> None:
"""初始化Ollama组件"""
self.llm = OllamaLLM(model=self.config.model, base_url=self.config.base_url)
self.embeddings = OllamaEmbeddings(model=self.config.embedding_model, base_url=self.config.base_url)
class LLMClient:
"""LLM客户端工厂"""
def __init__(self, provider: str = "ollama", **kwargs):
self.provider = provider
self.config = LLMConfig(provider=provider, **kwargs)
self._client = self._create_client()
def _create_client(self) -> BaseLLMClient:
"""创建具体的LLM客户端"""
if self.provider == "ollama":
return OllamaLLMClient(self.config)
elif self.provider == "openai":
return OpenAILLMClient(self.config)
else:
raise ValueError(f"不支持的LLM提供商: {self.provider}")
|
3. 文档处理模块 (doc_proc/)
文档处理模块负责文档的加载、分块和预处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| class MultilingualChunker:
"""多语言文档分块器"""
def __init__(self, chunk_size: int = 1000, chunk_overlap: int = 200):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?", " ", ""]
)
def clean_base64_data(self, text: str) -> str:
"""清理文本中的Base64数据"""
base64_patterns = [
r'data:image/[^;]+;base64,[A-Za-z0-9+/=]+',
r'[A-Za-z0-9+/]{50,}={0,2}'
]
cleaned_text = text
for pattern in base64_patterns:
cleaned_text = re.sub(pattern, '[图片数据]', cleaned_text, flags=re.IGNORECASE)
return cleaned_text.strip()
def split_documents(self, documents: List[Document]) -> List[Document]:
"""分割文档"""
processed_docs = []
for doc in documents:
cleaned_content = self.clean_base64_data(doc.page_content)
doc.page_content = cleaned_content
chunks = self.text_splitter.split_text(cleaned_content)
for i, chunk in enumerate(chunks):
chunk_doc = Document(
page_content=chunk,
metadata={
**doc.metadata,
"chunk_id": i,
"total_chunks": len(chunks)
}
)
processed_docs.append(chunk_doc)
return processed_docs
|
4. 嵌入处理模块 (embed/)
嵌入处理模块负责文档的向量化和存储:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| class EmbeddingProcessor:
"""嵌入处理器"""
def __init__(self, collection_name: str, llm_provider: str = "ollama", **kwargs):
self.collection_name = collection_name
self.llm_client = LLMClient(provider=llm_provider, **kwargs)
self.chroma_client = chromadb.PersistentClient(path=settings.storage.chroma_db_path)
self._setup_collection()
def _setup_collection(self) -> None:
"""设置ChromaDB集合"""
try:
try:
self.collection = self.chroma_client.get_collection(name=self.collection_name)
logger.info(f"已获取现有集合: {self.collection_name}")
except:
self.collection = self.chroma_client.create_collection(name=self.collection_name)
logger.info(f"已创建新集合: {self.collection_name}")
except Exception as e:
logger.error(f"集合设置失败: {e}")
raise
def process_documents(self, documents: List[Document]) -> None:
"""处理文档并存储到向量数据库"""
texts = [doc.page_content for doc in documents]
embeddings = self.llm_client.generate_embeddings(texts)
metadatas = []
ids = []
for i, doc in enumerate(documents):
metadata = {
**doc.metadata,
"embedding_model": self.llm_client.config.embedding_model,
"processed_at": datetime.now().isoformat()
}
metadatas.append(metadata)
ids.append(f"doc_{i}_{hash(doc.page_content) % 1000000}")
self.collection.add(
embeddings=embeddings,
documents=texts,
metadatas=metadatas,
ids=ids
)
logger.info(f"成功处理并存储 {len(documents)} 个文档块")
def query_similar(self, query: str, n_results: int = 5) -> List[Dict]:
"""查询相似文档"""
query_embedding = self.llm_client.generate_embeddings([query])[0]
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=n_results
)
formatted_results = []
for i in range(len(results['documents'][0])):
formatted_results.append({
'content': results['documents'][0][i],
'metadata': results['metadatas'][0][i],
'distance': results['distances'][0][i] if 'distances' in results else None
})
return formatted_results
|
关键技术实现
1. 智能文档分块策略
文档分块是RAG系统的关键环节。我们采用了以下策略:
- 递归字符分割: 使用
RecursiveCharacterTextSplitter,支持多种分隔符
- 多语言支持: 针对中英文混合文本优化分隔符
- 元数据保持: 在分块过程中保持原始文档的元数据
- Base64清理: 自动清理文档中的Base64编码图片数据
2. 向量检索优化
- 相似度计算: 使用余弦相似度进行向量匹配
- 元数据过滤: 支持基于文档类型、来源等元数据进行过滤
- 结果排序: 按相似度降序排列检索结果
3. 错误处理机制
我们实现了分层的错误处理系统:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class BaseError(Exception):
"""基础异常类"""
pass
class LLMClientError(BaseError):
"""LLM客户端错误"""
pass
class DocumentProcessingError(BaseError):
"""文档处理错误"""
pass
class EmbeddingError(BaseError):
"""嵌入处理错误"""
pass
|
4. 配置管理
支持多种配置方式:
开发过程中的关键决策
1. 模块化设计
决策: 将系统拆分为多个独立模块
理由:
- 提高代码可维护性
- 便于单元测试
- 支持功能扩展
- 降低模块间耦合
2. 抽象基类设计
决策: 为LLM客户端和文档加载器设计抽象基类
理由:
3. 配置验证
决策: 在配置类中添加验证逻辑
理由:
- 及早发现配置错误
- 提供清晰的错误信息
- 避免运行时错误
4. 日志系统
决策: 实现统一的日志系统
理由:
性能优化
1. 批量处理
文档处理和嵌入生成采用批量处理方式,减少API调用次数:
1
2
3
4
| def process_documents(self, documents: List[Document]) -> None:
texts = [doc.page_content for doc in documents]
embeddings = self.llm_client.generate_embeddings(texts)
|
2. 向量数据库优化
- 使用持久化存储,避免重复计算
- 支持增量更新
- 元数据索引优化
3. 内存管理
- 流式处理大文档
- 及时释放不需要的对象
- 控制批处理大小
部署和使用
环境要求
快速开始
1
2
3
4
5
6
7
8
9
10
|
pip install -r requirements.txt
export LLM_PROVIDER=ollama
export LLM_MODEL=qwen3:8b
export LLM_BASE_URL=http://localhost:11434
python main.py
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from embed.embedding import EmbeddingProcessor
processor = EmbeddingProcessor(
collection_name="my_docs",
llm_provider="ollama",
llm_model="qwen3:8b"
)
processor.process_directory("docs/")
query = "如何配置系统?"
results = processor.query_similar(query, n_results=3)
|
未来扩展方向
1. 功能扩展
- 多模态支持: 支持图片、音频等多媒体文档
- 实时更新: 支持文档的实时更新和增量处理
- 用户界面: 开发Web界面,提升用户体验
- API服务: 提供RESTful API接口
2. 性能优化
- 分布式处理: 支持大规模文档的分布式处理
- 缓存机制: 实现智能缓存,提高查询速度
- 索引优化: 优化向量索引结构
3. 智能化提升
- 自动分块优化: 基于内容语义的智能分块
- 查询理解: 改进查询理解和重写
- 答案生成: 优化答案生成的质量和准确性
总结
通过这个RAG文档问答系统的开发,我们深入理解了RAG技术的核心原理和实现细节。项目的成功关键在于:
- 合理的架构设计: 模块化、可扩展的架构
- 技术栈选择: 成熟稳定的技术栈
- 错误处理: 完善的错误处理和日志系统
- 性能优化: 针对性的性能优化措施
- 用户体验: 简单易用的接口设计
这个项目不仅解决了实际的文档问答需求,也为后续的AI应用开发提供了良好的基础架构。通过持续优化和扩展,我们可以构建更加智能和强大的AI应用系统。
参考资料
本文由 AI 辅助生成,如有错误或建议,欢迎指出。



